Architecture Overview¶
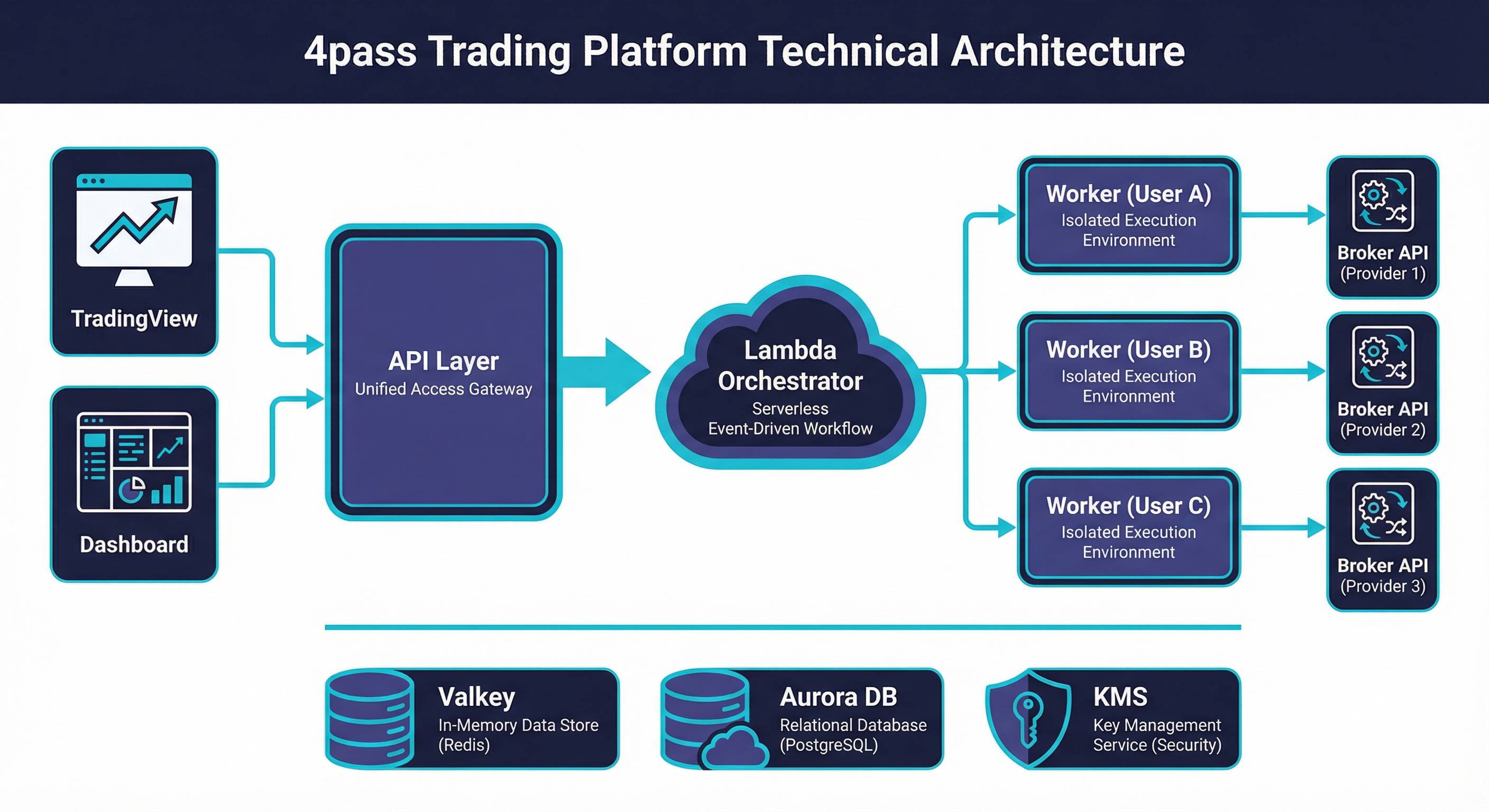
4pass is a production SaaS platform that bridges TradingView with multiple broker APIs, enabling automated order execution from Pine Script strategies. The system was designed from day one for horizontal scaling — every component is stateless, every bottleneck has a queue in front of it, and every scaling tier is a single Terraform variable change. Today it runs on AWS with per-user worker isolation, serverless orchestration, and a managed data layer that scales from a single user to 100,000+ with no architectural rewrites.
System Architecture¶
For the full detailed architecture, see Compute & Orchestration and Data Layer.
Why This Architecture — Business Outcomes¶
Every architectural decision maps to a business outcome:
| Technical Choice | Business Outcome |
|---|---|
| Per-user worker isolation | Zero cross-user risk — a broker crash or credential leak affects only one user; required by broker SDK session binding |
| Serverless orchestration (Lambda) | No single point of failure; zero operational burden; $8.50/month vs $30+ for a dedicated orchestrator instance |
| Bridge networking (60 tasks/instance) | 75% cost savings over Fargate; per-user cost of $1.61/month makes NT$999/mo pricing sustainable at 94.8% margin |
| Pool pre-warming (897ms) | Sub-second startup means no missed fills during volatile market moves — a direct impact on user trust and retention |
| Managed data layer (Valkey Serverless + Aurora) | Zero database ops; auto-scales from 1 user to 100K without capacity planning or DBA |
| Queue-driven everything (SQS FIFO) | Durable, ordered message delivery; no lost orders even during Lambda scaling events |
| Infrastructure as Code (~80 Terraform resources) | Entire environment reproducible in minutes; scaling to the next tier is a tfvars change, not a rewrite |
Design Principles¶
| # | Principle | Implementation |
|---|---|---|
| 1 | Per-User Isolation | Every active user gets a dedicated ECS task. Broker sessions, credentials, and failures never cross user boundaries. |
| 2 | Serverless Orchestration | Five Lambda functions handle all control-plane work — worker lifecycle, order tasks, maintenance, pool management. No long-running orchestrator process to fail. |
| 3 | Managed Data Layer | ElastiCache Valkey Serverless and Aurora PostgreSQL with RDS Proxy. Zero node management, automatic scaling, built-in HA. |
| 4 | Defense in Depth | WAF → ALB → application-level validation (4 layers on webhooks) → per-user credential encryption with KMS. Every layer assumes the one above it has been compromised. |
| 5 | Infrastructure as Code | ~80 Terraform-managed resources across ECS, Lambda, SQS, VPC, IAM, CloudWatch. Every environment is reproducible from a single terraform apply. |
| 6 | Cost Optimization at Every Layer | EC2 capacity providers over Fargate (75% savings), bridge networking for density (60 tasks/instance), Valkey Serverless over provisioned (pay per ECPU), pool pre-warming over cold starts (4x faster). |
| 7 | Bridge Networking for Density | Workers use bridge mode instead of awsvpc, sharing the host ENI. This removes the ENI-per-task limit and enables 60+ tasks on a single EC2 instance. |
| 8 | Queue-Driven Everything | SQS FIFO between API and Lambda decouples request ingestion from processing. No direct Lambda invocations from the hot path — all work flows through durable queues. |
Component Summary¶
| Component | Technology | Purpose | Key Metric |
|---|---|---|---|
| Frontend | Vue 3 + Vite | Dashboard, strategy management, account settings | SPA served from FastAPI static mount |
| API | FastAPI on ECS (m7g.large) | REST endpoints, webhook ingestion, authentication | 8 Gunicorn workers, <50ms p99 for auth routes |
| Orchestrator — worker_control | Lambda (Python) | Start/stop/claim workers via SQS FIFO | 50–500 concurrency, 897ms median cold-to-ready |
| Orchestrator — order_tasks | Lambda (Python) | Background fill verification, order state management | 50–500 concurrency, 180s visibility timeout |
| Orchestrator — maintenance | Lambda (Python) | Fan-out coordinator for orphan detection | EventBridge every 60s, single invocation |
| Orchestrator — maintenance_worker | Lambda (Python) | Process individual orphan marks/tasks | 100–500 concurrency, parallel execution |
| Orchestrator — pool_manager | Lambda (Python) | Scale pre-warmed worker pool to target size | EventBridge every 5m |
| Queue — worker-control | SQS FIFO | Worker lifecycle commands with message dedup | Visibility 90s, DLQ after 3 retries |
| Queue — order-tasks | SQS FIFO | Fill verification and order processing | Visibility 180s, DLQ after 3 retries |
| Queue — pool-claim | SQS Standard | Assign pooled workers to users | Visibility 10s, 5min retention |
| Workers | ECS EC2 (r7g.xlarge) | Per-user broker sessions, order execution | 60 tasks/instance, 64 CPU / 384 MB each |
| Cache | ElastiCache Valkey Serverless | Queues, heartbeats, sessions, rate limits, caches | Auto-scales 1 GB → 10 GB, 1K → 100K ECPU |
| Database | Aurora PostgreSQL + RDS Proxy | Users, accounts, orders, audit logs, sessions | Connection multiplexing, Multi-AZ ready |
| Encryption | KMS (RSA-4096) | Per-user credential encryption, HSM-backed | AES-256-GCM data keys wrapped with KMS master |
| Load Balancer | ALB + WAF | TLS termination, routing, rate limiting | Health checks every 15s, WAF 7 rules |
| Networking | VPC (2 AZ) | Public subnets for compute, private for data | Security groups enforce least-privilege |
Request Flow¶
A complete webhook order execution — from TradingView alert to broker fill:
Step-by-step breakdown:
- TradingView sends POST — Alert fires from a Pine Script strategy, payload includes the webhook token and signal data (action, symbol, quantity).
- ALB terminates TLS — ACM-managed certificate on the load balancer. Health checks run every 15 seconds.
- WAF checks rules — TradingView source IPs are exempted from rate limits. All other traffic passes through SQL injection, XSS, IP reputation, and rate limit rules.
- FastAPI validates (4 layers) — Token lookup → user resolution → trading account verification → signal parsing and normalization. Any failure returns early with an appropriate error.
- Check Redis for active worker — Look up
worker:active:{user_id}key. If present and TTL > 5s, worker is alive. - No worker? Start one (897ms) — API sends message to
worker-control.fifo→ Lambda picks it up → checks Redis for pool workers → sends claim viapool-claimqueue → pool worker receives, sets Redis mark. Total: 897ms median. FallbackRunTask: 3,659ms. Cold EC2: 45–60s. - Route order to Redis queue — Push structured order message to
trading:user:{user_id}:requestslist. - Worker pops and processes — Worker's event loop picks up the order within milliseconds via
BLPOP. - Call broker API — Worker uses its established broker session to place the order. Includes auto-reversal logic for position flipping.
- Response back via Redis — Worker writes the result to
trading:response:{request_id}with a 60s TTL. - Background fill verification — API queues a delayed check on
order-tasks.fifo. Lambda verifies the fill status with the broker 30–60 seconds later and updates the final state.
Why This Architecture¶
EC2 over Fargate — 75% Cost Savings¶
Fargate charges per-vCPU and per-GB at a premium. For worker tasks that need only 64 CPU units and 384 MB RAM, the Fargate overhead is enormous. A single r7g.xlarge (32 GB, 4 vCPU) at ~$0.258/hr runs 60 workers. The same 60 workers on Fargate would cost ~$1.00/hr. At scale, this is the difference between viable and unprofitable.
Bridge Networking — 60 Tasks per Instance¶
The default awsvpc mode assigns one ENI per task, hard-capped at ~3 per large instance (minus the host ENI). Bridge networking shares the host's network stack, removing this limit entirely. The trade-off is no per-task security groups — but workers only need outbound internet access to broker APIs, so this is acceptable.
Lambda over EC2 for Orchestration — No SPOF¶
A long-running orchestrator process is a single point of failure. If it crashes at 2 AM, no workers start. Lambda functions triggered by SQS and EventBridge are inherently HA — AWS manages retries, concurrency, and availability. The orchestrator has zero operational burden.
Valkey Serverless — Auto-Scaling ECPU¶
Provisioned ElastiCache requires capacity planning and over-provisioning for peak. Valkey Serverless scales from 1,000 ECPU to 100,000+ automatically, billing only for consumed compute. During off-hours, costs drop to near-zero. During market open (thousands of simultaneous orders), it scales without intervention.
The Architecture Thesis
Every component was chosen to minimize operational toil at the current scale while preserving a clear upgrade path to the next order of magnitude. No component requires replacement to reach 100K users — only configuration changes.